
https://simonezz.tistory.com/109
[논문 리뷰] Using Deep Learning to Win the Booking.com WSDMWebTour21 Challenge on Sequential Recommendations - 1
카페에서 빈둥빈둥 서핑을 하며 자유시간을 즐기다가 페이스북 그룹 Recommender System KR에 한 분이 올려주신 소개글을 보고 재밌어보여서 리뷰를 해보고자 한다. 부킹닷컴에서 주최한 Challenge(WSDM W
simonezz.tistory.com
1편에 이어 논문 리뷰를 이어가보겠습니다.
4. XLNet with Session-based Matrix Factorization head (XLNet-SMF)
XLNet-SMF는 XLNet으로 이름붙여진 Transformer 구조를 사용한다.
XLNet은 원래는 permutation-based language 모델링 task에 사용되는 방식이다.
이 경우에서는 word token의 시퀀스를 모델링하는 대신에 session(=trip)의 item(=city)의 시퀀스를 모델링하게 된다.
저자들은 XLNet 학습 task를 Masked Language 모델링에 적용시켰는데(BERT4Rec에서 사용한 방식), 이 접근방식에서 각 학습 step마다 일부 아이템(=city)이 마스크처리된다. 그 다음 마스크처리된 아이템의 원래 아이디는 시퀀스의 양쪽의 다른 아이템을 사용해서 예측된다.
(BERT에서 MLM를 사용하는 방식과 같은 맥락)
https://simonezz.tistory.com/68?category=892980
[논문 리뷰] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Abstact BERT는 대부분의 Language Representation model들과 달리, unlabeled text를 이용하여 모든 레이어에서 양방향 문맥을 이용하여 deep bidirectional representations를 미리 학습시킨다. 그 결과, 사전..
simonezz.tistory.com
이 부분이 신기했다. 문장이 word의 sequence인 것 처럼 여행이 아이템(=도시)가 이어진 sequence로 보고 언어모델링 방식을 적용하는 것이 알고나면 자연스러운데 BERT2Rec 논문을 아직 안읽어본 나로서는 이 부분이 인상깊었다.
이 방법은 마스크처리된 아이템이 마지막 아이템이 아닐 때 training시 여행에서 미리 미래 예약의 정보를 사용하게 되는데, inference시에는 마지막 item만 마스크처리하여 사용한다.
(미리 미래의 정보를 알려주면 안되기 때문에)
이 네트워크에서 각 예제는 여행이 되고 이는 예약들의 sequence 형태이다.
Reservation embedding은 features를 concat하고 MLP layers를 project함으로써 만들어지게 된다.
마지막으로 Matrix Factorization head(trip 임베딩과 city 임베딩을 dot product함)를 사용하여 sequence에서의 masked items에 대한 도시들(=items)의 확률 분포를 만들어낸다.
Ensembling
앙상블은 모델의 정확성을 높이는 검증된 방식인데, 각 모델들로부터 나온 값들을 통합해서(ex. weighted sum, sum 등) 좀 더 일반화된 값을 얻는 방식이다.
저자들은 k-fold cross-validation과 bagging(모델들을 여러개의 random seed에서 여러번 학습시키는 방법) 방식을 사용해서 위에서 설명한 세 개의 모델들을 앙상블했다.

일반적으로, 모델 예측의 다양성이 높을수록 앙상블 기법의 효과가 더 크다고 한다.
(모델들이 다 같은 값만 예측하면 앙상블의 의미가 없기 때문)
논문의 경우, 세 개의 구조에서 두 개씩 combinations하여 예측된 city scores의 상관관계는 대략 80%였다고 한다.
예측치를 평균내어 세 모델들을 앙상블하는 데에 더해서, 저자들은 또다른 앙상블 layer를 추가해보기도 했는데, 평균낸 예측치를 기준으로 나온 top 20개의 도시들을 rerank하는 방식이다. 결론적으로 precision@20에서 0.777의 평균 예측치를 보였고 이는 precision@4에서 0.57정도가 나온 값보다 훨씬 높은 수치이다.
(보통 precision@k에서 k가 커질수록 값이 더 커지는 게 당연한거 아닌가?)
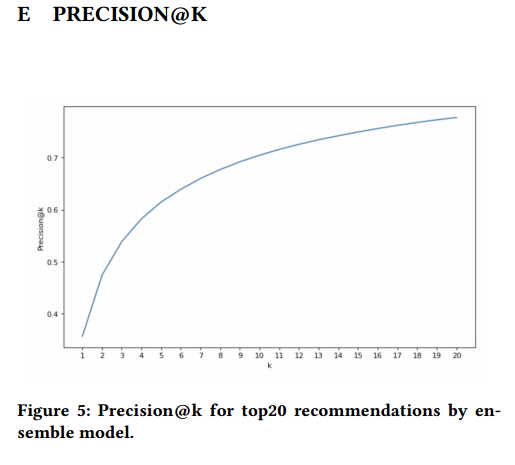
Reranking하는 방식은 gradient boosted decision tree 모델을 사용했으며 binary classification task형태로 사용했다.(0이면 incorrect, 1이면 correct)
*이 방법이 더 잘나오긴 했는데 이 대회 특성상 여러번 제출이 불가해서 그냥 weighted averaged 예측값들을 최종적으로 사용했다고 한다.
Results and Discussion
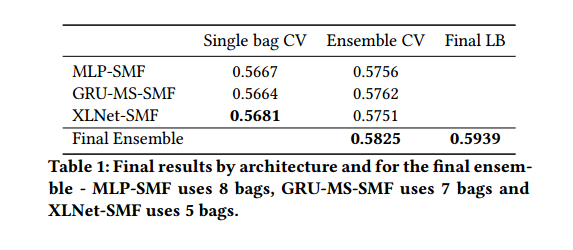
결론적으로는 앙상블을 통해 최종 예측을 했으며 싱글 모델로 사용했을 때는, XLNet-SMF이 가장 정확한 값을 보여줬다.
흥미로운 점은, MLP-SMF 구조는 CV score 측면에서 GRU나 XLNet을 사용했을 때 만큼의 성능을 보여줬다는 것이고 다른 모델들에 비해 모델 자체가 가볍기 때문에 학습하는 데에도 제일 시간이 적게 들었다.
세 개의 모델 모두 Session-based MF head를 사용했으며 여행 순서를 뒤집음으로써 데이터 augmentation을 했다. 각 component가 얼마나 성능에 영향을 끼쳤는지를 보기 위해 다음의 ablation study도 진행했다.


Conclusion
이 논문에서 저자들은 Booking 닷컴에서 주최한 챌린지에서 1등을 차지한 솔루션에 대해 소개했으며 이는 MLP, GRU 그리고 Transformer를 결합한 형태였다. 또한 각 모델에 Session-based Matrix Factorization head를 적용시켜 성능을 높였다.
추천 논문은 오랜만에 읽었는데 자연어에서 많이 사용되는 기법이 거의 그대로 추천쪽에서 적용되는 것이 재밌었다. 아무래도 여행과 문장 모두 sequence의 형태라 적용이 쉽게 가능했던 것 같다.
이 논문에서 언급한 GRU2Rec와 BERT2Rec도 한 번 읽어봐야겠다.
댓글