
오늘은 Tabular data 학습에 사용되는 TabNet이라는 모델 논문을 읽어보았다.
원 논문을 깔끔하게 요악한 towarddatascience글도 있어서 같이 참고해보았다.
Introduction
XGBoost, LightGBM 그리고 Catboost같은 Gradient Boosting Model이 계속해서 tabular data 학습측면에서 인기를 얻고있는데, 구글이 2019년에 낸 TabNet은 Neural Network중 하나로 tree기반의 모델들보다 많은 벤치마크 데이터에서 우수한 성능을 보여줬다. 성능이 우수한 것뿐만이 아니라 설명도 가능한 모델이다. 그런데 왜 인기가 없을까나!?!(심지어 feature preprocessing도 필요없음)
TabNet balances explainability with state-of-the-art performance. It is easy to implement and requires limited hyperparameter tuning. So why is XGBoost still the Kaggle Grandmaster weapon of choice?
TabNet은 설명가능성과 성능사이의 균형을 이루는데, 실행하기도 쉽고 hyperparameter tuning도 크게 필요없다. 그런데 왜 XGBoost가 여전히 Kaggle과 같은 대회에서 우위를 점하고 있을까?
일단 TabNet이 어떤건지 알아보자.
What is TabNet?
1. TabNet은 tabular data를 전처리없이 사용하며 gradient decent기반의 optimization으로 학습된다.
2. TabNet은 각 decision step에서 sequential attention으로 feature를 선택하는데, 이는 해석을 용이하게하고 더 학습이 잘되게 한다.(자세히는 뒤에 나옴)
3. Feature selection은 instance-wise로 하는데, 예를들어 학습 데이터셋의 각 row마다 feature selection을 다르게 한다.
4. TabNet은 feature selection과 추론에 single deep learning architecture 형식이다. (a.k.a. soft feature selection)
5. 위의 TabNet 디자인때문에 TabNet은 local / global interpretability를 둘다 갖는다.

Steps
위 TabNet그림은 Step별로 구분이 되어있는데, 이 Step은 여러 componets(ex. Attentive Transformer, Mask..)등으로 이루어진 block으로 Step을 몇개쓸건지도 hyperparameter이다.(tree depth와 비슷한거라고 생각하면 될 듯)
당연히 Step수를 늘리는건 learning capacity를 증가시키지만 학습시간과 메모리 사용량, 그리고 overfitting확률도 같이 올라간다.
각 Step은 최종 분류에서 각각의 투표를 받고 이 투표는 동일하게 합산된다.(weighted sum X)
ensemble classification과 같은 방식이다.
Feature Transformer
Feature Transformer는 자체 architecture를 가지는 network다.
여러개의 layer를 가지는데, 일부 layer는 매 Step에서 공유되고 나머지는 각 Step에만 있는 unique한 layer이다.
각 layer는 fully-connected layer, batch normalization 그리고 Gated Linear Unit activation을 가지고 있다.

저자는 decision step들사이에 몇개의 레이어를 공유하는게 parameter-efficient 그리고 robust learning with high capacity 을 가능하게 만든다고 한다. 그리고 root 0.5로 normalization하는게 variance를 드라마틱하게 바꾸지않고 학습을 안정적으로 만들게 한다고 한다.
Feature Selection
Features가 한번 transformed되면 Feature selection을 위해 Attentive Transformer와 Mask로 넘겨진다.
Attentive Transformer는 fully connected layer, batch normalization 그리고 Sparsemax normalization으로 구성되어 있다. 또, Prior Scales를 포함하고 있는데 Prior Scales가 뭔지는 아래 와 같다.
it knows how much each feature has been used by the previous steps.
각 feature가 이전 step에서 얼마나 사용되었는지(얼마나 중요한지) 알고 있다는 것이다. Prior Scales는 이전 Feature Transformer로부터 처리된 features를 사용하여 Mask를 도출하는데 사용된다.
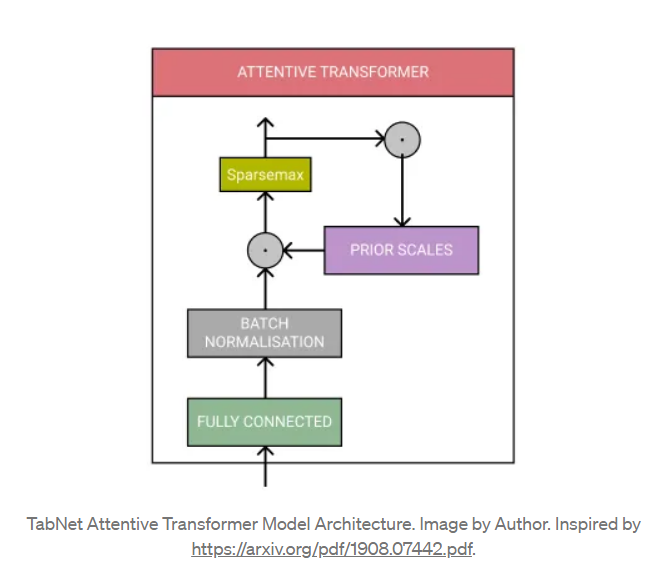
Mask는 모델이 가장 중요한 feature에 집중하도록하며 설명가능성을 도출하는데에 사용된다. (그래야 어떤 feature가 중요한 역할을 했는지 알 수 있다.) = 몇개의 feature를 가림으로써, 모델은 Attentive Transformer에 의해 중요하게 여겨지는 features를 사용할 수 있게된다.
TabNet employs soft feature selection with controllable sparsity in end-to-end learning
이는 한 모델이 feature selection과 output mapping을 같이 수행하며 더 나은 성능을 보여주는 걸 의미한다.
TabNet uses instance-wise feature selection, which means features are selected for each input and each prediction can use different features.
각 input과 각 prediction에서 feature가 선택되는 instance-wise feature selection은 필수적이라고도 한다.
Explainability
TabNet이 Boosted Trees에 비해 가지는 강점은 더 설명가능하다는 것이다. Gradient boosting모델들은 보통 왜 그런 결과가 나왔는지 해석하려면 SHAP나 LIME과 같은 걸 사용해야하는데 TabNet은 masking을 통해 어느정도 설명이 가능하다.
Masks
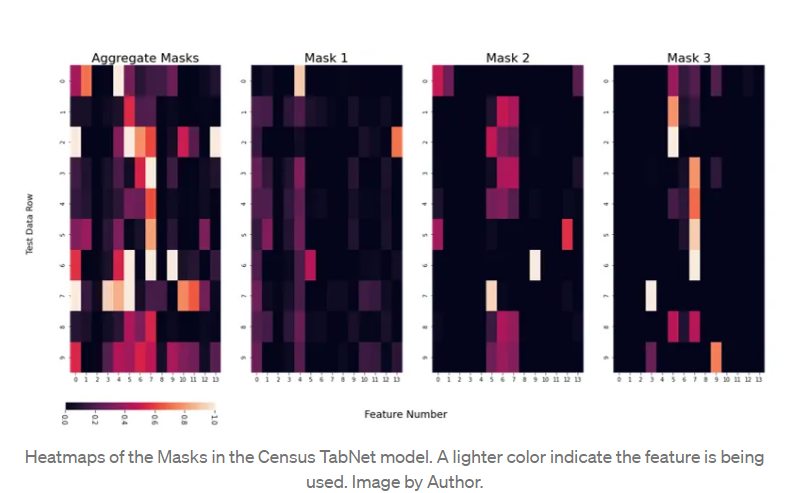
Mask를 사용함으로써 어떤 feature가 예측할 때 사용되었는지 알 수 있는데,
아래 예시로 보면 Mask1(두번째 그림)은 row0에서 4번째 feature를 중요하게 생각한다는 것을 알 수 있다.
Mask를 통해 이렇게 어떤 feature를 모델이 예측하는데에 사용했는지는 알 수 있지만 이것이 어떻게 실제 feature value에 관련되었는지는 명확하지 않다. (단순히 값이 낮거나 높다고해서 모델이 feature를 사용했는지는 알 수 없다.)
※ 또한, 논문저자들은 모델 weights를 사전학습하고 필요한 학습 데이터 양을 줄이기 위해 Self-supervised learning을 제안했는데, 이를 위해서는 dataset의 features는 mask처리되고 모델은 mask처리된 부분을 예측해야한다. (그 후에 decoder가 result를 만들어낸다.)
Conclusion
TabNet is a deep learning model for tabular learning. It uses sequential attention to choose a subset of meaningful features to process at each decision step. Instance-wise feature selection allows the model’s learning capacity to be focused on the most important features and visualisation of the model’s masks provide explainability.
정리하자면, TabNet은 tabular data를 학습하는 모델이며 1)Sequential attention을 통해 의미있는 features를 찾아낸다. 또한, 2)Instance-wise feature selection을 통해 모델 학습 capacity가 더 중요한 feature에 초점을 맞추도록 하며,
3)Mask를 통해 더 결과를 설명가능하게 만든다.
참고 : https://towardsdatascience.com/tabnet-e1b979907694
TabNet: The End of Gradient Boosting?
TabNet is a unique approach to applying Neural Networks to Tabular data. It is high performing and interpretable, using Sequential Attention to select salient features.
towardsdatascience.com
https://github.com/dreamquark-ai/tabnet
GitHub - dreamquark-ai/tabnet: PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf - GitHub - dreamquark-ai/tabnet: PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
github.com
GitHub - dreamquark-ai/tabnet: PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf - GitHub - dreamquark-ai/tabnet: PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
github.com
'개발 > 그 외' 카테고리의 다른 글
| [논문리뷰] LARGE-SCALE CONTRASTIVE LANGUAGE-AUDIO PRETRAINING WITHFEATURE FUSION AND KEYWORD-TO-CAPTION AUGMENTATION(CLAP) (0) | 2024.01.20 |
|---|

댓글