
LLM활용한 추천시스템 코드를 보다보니 CTR 모델들에 대해 제대로 모르고 있는 듯하여
이참에 정리를 해보려 한다. 사실 각각의 게시물로 쓰려고 했는데, 서로 비교하는 데에는
한 게시물로 정리하는 것이 나을 것 같아 정리해본다.
CTR(Click Through Rate)는 영어 그대로 클릭할지 안할지 예측하는 Task이다.
광고나 이커머스 쇼핑에서 CTR을 잘 예측해야 알맞게 추천할 수 있다.
1. DIN

- 기존 CTR모델들은 embedding&MLP 방식으로 진행함. 즉, vector를 저차원으로 임베딩한 뒤 MLP에 넣음
→ 고정된 길이의 vector이니 정보손실 일어남. 다양한 선호도 파악 어려움
- 기존 다른 RNN기반의 모델들은 데이터사이가 거리가 멀어질수록 연관관계가 줄어들어 데이터를 적절하게 활용할 수 없음.
- RNN+attention기반으로 유저 행동의 변화를 예측
- 한계점 : Sequential 행동들간의 연관성 파악 어려움.
- 모델구조
1) Embedding Layer : User Profile Features를 input으로 저차원의 벡터로 변환
2) Local Activation Layer : Candidate item와 User behaviors간의 연관성 계산.
3) MLP Layer : Embedding Layer, Activation Layer, Context Features를 concat하고 Flatten한 뒤 MLP에 넣음
최종적으로 item선호도 계산.
2. DIEN(Deep Interest Evolution Netweork)

- 이전 CTR모델들은 interaction에만 집중
- DIEN은 유저들의 변화하는 interest에 집중함
- 방법론
1) 각 학습단계마다 auxiliary loss를 활용해서 유저의 latent interest 포착
2) 유저의 관심사가 변하는 현상에 집중하기 위해 interset evolving layer제안
3) GRU의 update gate에 attention을 적용하는 AUGRU알고리즘 활용
→ 유저의 변화하는 흥미를 더 잘 파악
- 왜 개발했나?
1) 기존 RNN기반 모델의 loss는 모든 hidden state를 거친다음에 적용되는데, 이건 유저의 모든 행동을
연속적으로 동일하게 다룬다는 문제가 있음(중요도 파악X, 비연속성 고려X)
2) 각 hidden layer에 대한 loss를 적용하는 방법이 필요함 → auxiliary loss
- 모델 구조
1) Embedding Layer
: User profile, User Behavior, Ad(Target), Context를 one-hot encoding vector로 바꿈
→ e차원 벡터로 embedding (embedding vector는 모두 concat)
2) output : CTR binary classification(click or not)
: 마지막 output은 그래서 이 user가 target을 누를거냐 아니냐로 나온다.(0/1)
3) Interest extract layer - GRU with auxiliary loss & negative sampling
: Sequence정보를 학습하기위해 GRU모델 선택.
- Auxiliary loss란?

파란부분과 같이 중간에 Auxiliary Loss를 적용하는 방식.
RNN을 사용하는 모델은 Sequence길이가 길어지면, 제대로 각 단계에서의 행동이 반영이 안되므로
중간 hidden state의 auxiliary gradient를 계산하고 loss를 적용함.(Training할때만 적용)
- Negative Sampling은 다른 방법론에서도 많이 나오듯이 이 유저가 클릭한 상품외에 상품 벡터도 가져와서
이 상품에 대한 output은 0이 나오도록 학습하는 방법이다.
4) Interest evolving layer : Attention & GRU
: 고객의 interest는 다양하고 계속 변함(갑자기 어떤날은 뜬금없는 것에 흥미를 느낄수도..)
→ 마지막 선택 당시에 가장 연관있는 걸 줘야함(attention)
→ 전체 Interest의 진화 트렌드에 따라 예측가능(GRU-sequential)
- Attention
: 타겟 상품에 대한 embedding vector가 key로 들어가서 dot product
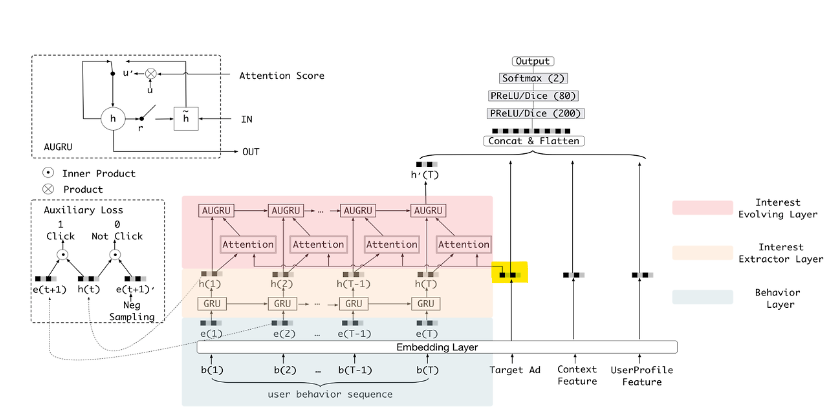
→ 현재 시점(t)에서의 유저 행동 h(t)와 Target Ad사이의 연관도를 파악.
밀접한 관계가 있을 수록 attention score가 크게 나옴.
- GRU
1) 기본 GRU
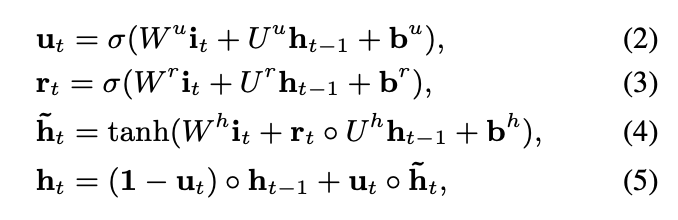
u : update gate(t시점의 정보를 얼마나 반영할지)
r : reset gate(지난 정보를 얼마나 버릴지)
h~ : 과거의 데이터를 얼마나 사용할 것인지
h : u를 weight로 해서 과거 데이터랑 직전시점 데이터랑 weighted sum
2) AUGRU
: GRU에 attention 결합
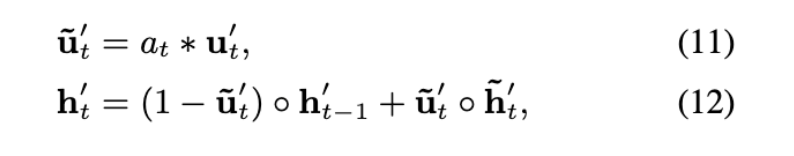
u대신에 a(attention score)를 적용해서 weight로 활용. 즉, 현재(t)시점의 h값이 중요하다면 weight를 강하게 줌.
3. DCN(Deep & Cross Network)
- 보통 모델에서 사용되는 feature는 sparse&large이므로 효과적인 feature를 조합하여 의미있는 feature를 찾는건 exhaustive search를 요구하며 비효율적이다.(의미없는 interaction도 학습함)
- DCN은 implicit한 모델은 explicit하게 표현하여 interaction 학습
- 구조 : Deep network와 Cross network로 이루어져 있음. 같은 input을 공유하며 마지막에 두 output을 쌓아서(stack)해서 예측 확률 계산.
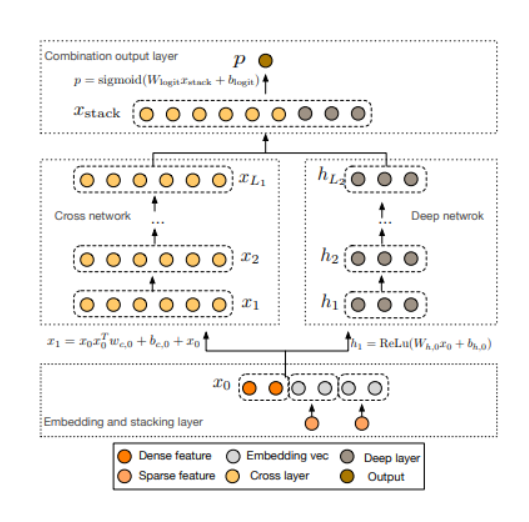
- Cross Network
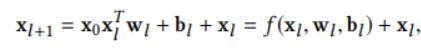
x0xlT를 통해 interaction 계산 → w(가중치)를 곱하고 bias를 더해줌 → residual connecion인 xl을 더해줌.
- Deep Network : 전형적인 feed-forwrad neural network로 linear&actionvation function 조합.
2탄에는 DeepFM, xDeepFM, AutoInt, FiBiNet, FiGNN에 대해 알아볼 예정.
참고
https://katenam32.tistory.com/9
[논문리뷰] Deep Interest Network for Click-Through Rate Prediction
katenam32.tistory.com
https://huidea.tistory.com/284
[Deep learning] [논문리뷰] DIEN - Deep Interest Evolution Network for Click-Through Rate Prediction (CTR 추천알고리즘,
1. Introduction 2. Related Work 3. DIEN : Deep Interest Evolution Network 1) BaseModel * feature representation * Embedding, MLP * Loss function 2) Interest Extractor Layer * auxiliary loss 3) Interest Evolving Layer * augru 4. Experiements 5. Conclusion 1
huidea.tistory.com
https://velog.io/@kida/DCN-DeepCross-Network
[DCN] Deep&Cross Network
DNN은 자동적으로 모든 feature의 interaction을 학습한다. Implicit하게 모든 interaction을 학습하는 과정에서 의미 없는 interaction을 학습하면서 학습 성능이 떨어지는 현상이 발생하기도 한다. DCN에서는
velog.io



댓글