
Abstract
이 논문에서는 다양한 라벨링되지 않은 데이터로 pre-training을 시킨 후 특정 task에 맞춘 fine-tuning 과정을 거치는 단계를 가진다. 이전의 방법론들과는 달리 모델구조를 최소한으로 변화시키고 효과적인 Transfer를 얻기 위한 fine-tuning 단계에서 과제에 맞는 Input representations을 사용하였다. 다양한 실험 결과를 통해 이 접근이 다양한 과제에 대해 효과적임을 증명하였다.
이 논문에서 task에 대한 사전 지식이 없는(task-agnostic) 모델은 특정과제에 특화된 모델 성능을 뛰어넘는다. 테스트된 12개의 tasks 중 9개에서 SOTA 수준의 성능을 달성하였다.
1. Introduction
라벨링 되지 않은 raw 데이터의 텍스트에서 효과적으로 학습하는 능력은 NLP에서 supervised learning에 대한 dependency을 낮추는 데 있어 매우 중요한 부분이다. 대부분의 딥러닝 방법은 라벨링된 방대한 양의 데이터를 필요로 하여 학습하는데 이는 많은 자원이 필요하기 때문에 응용에 제한이 두게 된다. 이러한 상황에서 라벨링되지 않은 데이터로부터 정보를 얻어낼 수 있는 모델은 자원을 들여 라벨링된 데이터를 만드는 것의 훌륭한 대안책이 되고, 오히려 supervised learning에서보다 더 좋은 결과를 얻기도 한다. 사전학습된 word embedding이 그러한 예시 중 하나이다.
그러나, 라벨링되지 않은 텍스트 데이터에서 단어 수준 정보 이상을 얻는 것은 두가지의 한계점을 가진다.
- 어떤 objective function이 transfer에 유용한 text representation을 배우는 과정에서 효과적인지 명확하지 않다. 최근 연구들에서 다양한 objective function을 사용함으로써 더 나은 성능을 보여준 예시가 있기 때문이다.
- 학습된 representation을 다른 task로 transfer하는 가장 효과적인 방법에 대한 명확한 의견이 없다. 대부분의 기존 방법들은 모델에 task-specific한 변화가 필요하다.
이러한 한계점들로 인해 NLP에 대한 효과적인 semi-supervised learning의 개발은 어려움이 있다.
이 논문에서는 unsupervised pre-training과 supervised fine-tuning을 사용하여 언어이해 과제를 위한 semi-supervised 접근법을 연구하였다. 약간의 fine-tuning으로 다양한 과제에 전이를 통해 사용이 가능한 범용적인 representation을 학습하는 것이다. 라벨링되지 않은 대량의 말뭉치와 라벨링된 데이터를 갖는 여러 dataset를 가정한다.
학습은 다음의 두 단계를 거친다.
- 모델의 초기 parameter를 학습하기 위해 라벨링되지 않은 데이터에 대한 objective function를 사용한다.
- 학습된 parameter를 supervised objective function을 사용하여 목표 task에 적용시킨다.
모델에서는 기존 많은 task에서 상당한 성능을 보인 Transformer를 사용한다. transformer는 RNN, LSTM에 비해 장거리 의존성을 다루는 데 뛰어나 더 많은 구조화된 memory를 쓸 수 있게 한다. transfer 중에는 traversal-style 접근법에서 얻은 task-specific 입력적응을 이용하며 Input은 하나의 일련의 ‘연속의 token’으로 주어진다. 이 방법은 사전학습된 모델의 구조를 최소한으로 바꾸게 한다.
이 접근법을 네 가지(자연어추론, Q&A, 의미 유사성, 문서분류)과제에 대해 평가한다. 이 모델은 12개 중 9개의 과제에서 SOTA수준의 결과를 보인다.
3. Framework
학습은 두 단계로 진행된다.
- 라벨링되지 않은 대량 데이터를 이용하여 큰 언어모델을 학습
- 라벨링 데이터를 이용하여 특정 task에 맞춰 모델을 fine-tuning
3.1. Unsupervised pre-training
token의 라벨링되지 않은 데이터 주어질 때, 다음을 최대화하도록 objective funtion을 사용한다:
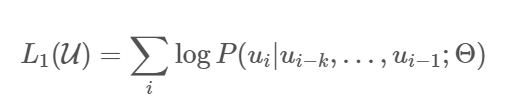
는 context window이고 조건부확률 는 parameter가 인 신경망을 사용하도록 설계되었다. 이 function은 SGD를 이용하여 최소화된다.
또한, GPT는 앞서 언급했듯이, Transformer의 변형인 multi-layer Transformer decoder를 사용한다.
이 모델은 입력 문맥 token에 multi-headed self-attention을 적용 후, 목표 token에 대한 분포를 얻기 위해 position-wise feedforward layer를 적용한다.


n은 layer의 수, 는 token embedding 행렬, Wp는 position embedding 행렬이다.
3.2. Supervised fine-tuning
위 모델을 학습한 후, parameter를 task에 맞춰 fine-tuning한다. 라벨링된 dataset C가 있고 각 원소가 일련의 입력 token 및 label y로 되어 있다고 하자. 입력은 최종 transformer block의 활성값 hlm을 얻기 위해 pre-trained 모델에 전달되고 이 output 다시 label 를 예측하기 위해 parameter 와 함께 linear layer로 전달된다.
이는 다음을 최대화한다.
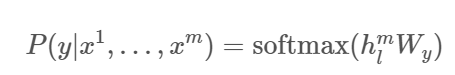

fine-tuning 단계에 언어모델을 보조 objective function으로 포함시킴으로써 다음 이유로 학습을 돕는다.
- supervised 모델의 일반화(범용성)를 향상시키고
- 수렴을 가속화한다. 즉 목적함수의 critical point로...
구체적으로, parameter 에 대해 다음 목적함수를 최적화한다:

즉, fine tuning 단계에서 추가된 parameter는 과 구분자 token을 위한 embedding 뿐이다.
3.3. Task-specific input transformations
텍스트 분류와 같은 과제에 대해서는 fine-tuning이 위에 언급한 방법으로 가능하다. 그러나 Q&A와 원문함의와 같은 과제에서는 Input이 문장의 2~3개 pair인 형태가 될 수도 있고 많이 다르므로 이를 따로 처리해주어야 한다.
아래 Figure 1에 이에 대한 방법이 나와 있는데, 질문/텍스트/선택지/가정/전제 등을 하나씩 따로 구분자를 이용하여 구분하여 하나로 연결하는 방식을 쓴다.
Textual entailment
함의 문제에서는 전제 p와 가정 h를 구분자 $로 연결하였다.
Similarity
두 개의 텍스트의 순서가 없으므로 두 개를 다른 순서로 이어붙여 총 2개를 입력으로 쓴다. (data argumentation 맥락)
이는, Transformer에 각각의 입력으로 들어간다.
Question Answering and Commonsense Reasoning
문맥 문서 z, 질문 q, 가능한 답변이 ak라 하면, [z; q; $; a_k]로 연결하고 Input 개수는 답변의 개수만큼 생성된다.

뒤의 내용은 다음 포스팅에서 다루겠습니다.
'개발 > NLP(Natural Language Processing)' 카테고리의 다른 글
| [논문 리뷰] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks - 2 (0) | 2021.03.10 |
|---|---|
| [논문 리뷰] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks - 1 (1) | 2021.03.07 |
| [논문 리뷰] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2021.01.20 |
| [논문 리뷰] Attention Is All You Need, Transformer (0) | 2021.01.09 |
| fastText란 무엇인가? (0) | 2020.11.21 |




댓글