
이번 강의는 Computer vision분야에서 어떤식으로 딥러닝을 사용하는 지에 대해 대략적으로 소개하는 파트들로 구성되어 있다. 2018년에 대학원 강의를 들으며 딥러닝이 어떻게 쓰이는지에 대해 구체적인 소개를 듣고 정말 무서움과 놀라움을 금치못했는데 최신 강의에서는, 그것도 미국에서는 어떻게 흐름을 소개하는지가 궁금하다.
(Lecture 6, 7은 보완해야할 부분이 많아 보완 후 다음주 주말 업로드 예정)
Part 1
이제까지는 딥러닝에 대한 core idea, 예를 들어 convolutoin, normalization등에 대해 다뤘다.
이번 강의에서는 어떻게 딥러닝이 쓰이는지, 특히 컴퓨터비전 분야에서 어떻게 쓰이는 지에 대해 다룬다.
앞서 본 내용들은 이미지가 들어가서 output value가 나오는 분류 문제에 대해 다뤘다.
하지만 컴퓨터비전에서는 분류외에도 많은 task가 있는데 예를 들어 자율주행차에서 사용되는 detection 문제나 이미지에서 물체들을 픽셀별로 구분해내는 segmentation등이 있다.
일반적인 컴퓨터비전 task들은 다음과 같이 나눌 수 있다.

사실 한 이미지에서 딱 한물체만 있기는 어렵기 때문에 이미지내에서 물체를 찾고 분류하는 task가 더 자연스럽다.(자료가 2018년에 내가 수업들을 때 봤던 예시랑 같아서 놀랍다.)
첫번째 Object Localization부터 살펴보자.
이미지 내에서 물체의 위치를 찾는 문제로 볼 수 있는데, 이전에 분류문제에서는 데이터가 (image, class)로 주어졌다면 여기서는 데이터가 (image, 물체 위치 좌표/높이/너비)로 주어진다.

이제 이러한 데이터로 학습시킨 모델의 정확성을 어떻게 측정할까?

기존에 분류문제에서는 그냥 맞게 class를 예측한 비율만 재면 됐었다.
Object Localization에서는 어떻게 측정할까?
사실 이 task자체가 bounding box를 제대로 예측하는 것이기 때문에 주어진 box와 예측한 box가 얼마나 겹치는 지에 대해 측정하면 될 것이다.
👉🏻 이에 사용되는 것이 Intersection over Union(IoU)이다.
이름에서도 알 수 있듯이, 분자는 박스가 겹치는 넓이가 되고 분모는 두 박스의 Union 넓이가 된다.
그럼 이 기준을 어떻게 정할까? 보통 IoU > 0.5면 정확하다고 예측한다고 한다.
🌟 여기서 주의할 점은 그냥 측정방법이지 이게 loss function은 아니라는 점이다.
Part 2
그럼 Object Localization은 어떻게 풀어야할까?

👉🏻 Regression문제로 풀 수 있다.
Cross entropy loss로 class label을 예측하고, Regression loss(예를 들면 Gaussian log-likelihood, MSE)로 bounding box의 좌표와 크기를 예측해낸다.
하지만 이런 방식은 사실 잘 사용되지 않는다고 한다.
(나중 강의에서 더 자세히 설명)
그럼 Bounding box예측을 어떻게 해야할까? 매 patch마다 분류를 해야할까?
👉🏻 Windows를 옆으로 밀면서 하는 방식인 Sliding Window가 있다.

두번째와 같이 이미지를 확대하고 patch별로 자른다고 생각해보자.

그다음 가장 class probability가 큰 박스를 선택한다고 생각해보자.
이를 더 일반적으로 말하자면 "Non-maximal suppression"이라고 한다.
(자세히는 detection 파트에서 나온다.)
좀 더 실용적인 방법으로는 OverFeat가 있다.

먼저 분류문제에 대해 사전학습하고 Regression을 각 영역을 다른 scale로 보내서 푸는 방식이다.
(이 논문은 아직 안 읽어봤는데 읽어봐야겠다.)

그럼 Sliding Window에 필요한 계산량은 어떻게 해결해야할까?
모든 가능성을 고려하는 방법이니 그만큼 계산량이 엄청날 것이다.
👉🏻 재사용하는 방법이 있다. 즉 많이 겹치는 박스면 굳이 또 계산하지 않고 재사용하는 것이다.

요약하자면 다음과 같다.

각 Bounding box마다 class와 좌표를 계산하는 Building block,
그다음 이 모델을 각 다른 스케일로 평가를 하는 방식,
마지막으로는 각 위치에서 각각 box마다 예측을 하는 방식이 아닌 이를 또다른 convolution으로 보고 계산함으로써 계산량을 줄이는 방식이다.
Part 3
이전의 Localization은 이미지내에 한 물체만 탐지하고 분류하는 문제였다면,
Object Detection은 이미지내에 여러 물체들을 탐지하고 분류하는 문제라 볼 수 있다.
어떻게 여러개를 계산해낼까?

이전처럼 Sliding window를 생각할 수 있다. 여기서는 가장 높은 확률의 window를 고르는 대신에 미리 정해놓은 threshold보다 확률이 큰 window의 물체를 뽑아내는 것이라 볼 수 있다.
여기서 큰 문제가 있는데, 높은 점수의 window는 아마도 근처에 높은 점수의 window가 있을 수 있기 때문이다. 예를 들어 한 박스에서 곰일 확률이 98%이지만 바로 옆 박스에서 여우일 확률이 99%일 수 있다.
여기서 이전에 언급된 Non-maximal suppression 이 등장한다. 근처에 다른 detection을 모두 무시하는 방법이다.
Detection의 output은 각 box의 좌표와 class가 된다.
가장 유명한 Detection 모델인 YOLO에 대해 알아보자.

이미지를 grid cells로 나누고 확률 map과 bounding box를 계산 후 앞서 배운 IoU(confidence), box의 좌표 (x, y, w, h) 그리고 class label l을 계산하는 방식이다.
YOLO도 마찬가지로 실제로 49개의 cell를 계산하지 않고 재사용하는 방식을 사용한다.
YOLO의 장점으로는 빠르다는 것이 있다. 정말 한큐에 계산을 함으로써 빠른 속도를 보여준다. 하지만 성능면에서는 SOTA가 아니다.
그럼 더 정확한 방법은 어떤 것이 있을까?
👉🏻 R-CNN방법이 있다.

CNN와 Region proposal을 합친 방법이라 볼 수 있다.
이는 YOLO보다 느린데, 이 속도문제를 이전에 배운 방식으로 개선할 수 있을까?
참고:simonezz.tistory.com/74?category=892979
[논문 리뷰] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
딥러닝 스터디에서 발표한자료입니다.
simonezz.tistory.com

이러한 Detection 모델에 대해 더 알고 싶다면 아래의 논문을 참고하기를 추천한다.

Part 4
이제 마지막 Segmentation에 대해 알아보자.
Segmentation은 각 pixel을 라벨링하는 방식이라 보면 된다.
문제는 우리가 input image와 같은 해상도를 원한다는 것이다.
그럼 그냥 downsampling을 안하면 되지 않을까?
👉🏻 계산량이 어마어마 해진다.
문제를 정의해보자면 다음과 같다.

이러한 문제를 위한 한 모델의 구조는 다음과 같다.

Downsampling후 다시 upsampling하는 방식이다.
여기서 Upsampling은 어떤식으로 계산되는 지에 대해 살펴보자.
말그대로 픽셀을 근사해서 해상도를 높이는 방법인데, 직관적으로 생각하면 일단 있는 픽셀값으로 만들어내야 하니 다음과 같이 계산된다.

이와 비슷하게 Un-pooling이라는 방법도 있다.

말그대로 Pooling을 반대로 하는 방식인데, Pooling으로 max-pooling을 했다면 주어진 patch에서 가장 큰 값을 가져온 식이므로 그 위치를 저장해두고 Unpooling시에 그 위치에 다시 값이 들어가는 형태이다.
다시 모델 구조로 돌아가서 보자면, 이미지가 들어오면 pooling을 하고 다시 upsampling을 하여 segmentation하는 방법임을 알 수 있다.

그럼 자연스럽게 또 이런 의문이 들 것이다.
어쨋든 Pooling을 하면 정보들이 없어지는데 segmentation에 중요한 pixel정보가 없어지는 건 어떻게 해야할까?
👉🏻 이에 대해 해결점을 제시한 모델이 U-net이다.
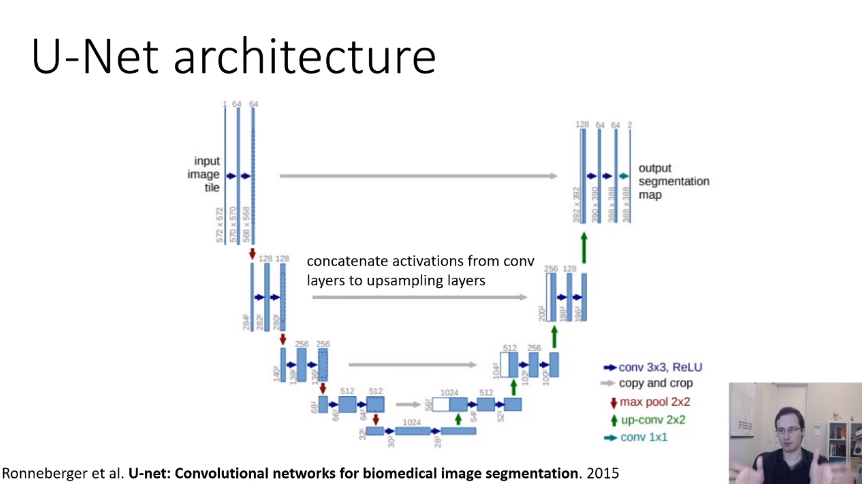
가운데 회색 화살표를 보면 왼쪽의 블록이 오른쪽으로 가서 하얀색의 블록으로 concat하는 것을 확인할 수 있다. 이렇게 정보를 보충해주는 방식으로 segmentation에 필요한 정보를 보완할 수 있게 된다.
이번 Lecture에 대해 요약하자면 다음의 4가지의 Computer Vision 이슈에 대해 다루었다.

끝!
'개발 > UC Berkely CS182' 카테고리의 다른 글
| [Lecture 10] Recurrent Neural Networks (0) | 2021.05.23 |
|---|---|
| [Lecture 9] Visualization and Style Transfer (0) | 2021.05.19 |
| [Lecture 7] Initialization, Batch Normalization (0) | 2021.05.02 |
| [Lecture 5] Backpropagation (6) | 2021.04.18 |
| [Lecture 4] Optimization (2) | 2021.04.11 |




댓글