
저번 포스팅에서는 SVD를 이용한 CF에 대해 다뤘다. 개인 맞춤형이 아닌 특정영화와 유사한 영화를 평점 행렬 기준으로 추천했었다.
이번 포스팅에서는 개인의 기존 평가를 기반으로 영화를 추천해주는 추천시스템을 구현해보자.

저번과 마찬가지로 MovieLens dataset을 이용한다.
필요한 데이터를 가져와서 보기 좋게 정리해보자.

여느때와 같이 csv파일을 읽어온다.
rating_data는 각 사용자의 각 영화에 대한 평점을 나타내고,

movie_data는 각 영화의 장르에 대해 나와있다.
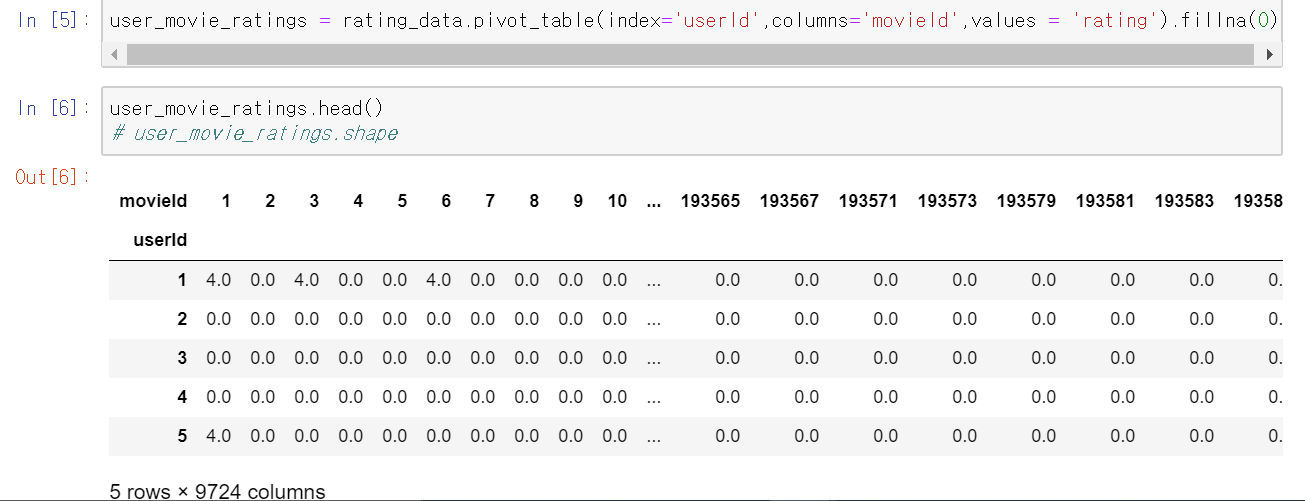
DataFrame의 피봇테이블을 이용해 왼쪽 인덱스는 userId, 각 column들은 movieId 그리고 값들은 평점으로 만들어준다.(값이 나와있지 않은 값은 .fillna(0)를 이용해 0으로 채운다.)
위와 같이 user-movie 테이블이 만들어진다.

.as_matrix를 이용하여 numpy matrix로 바꿔준다.
왜 numpy를 사용할까?
svd전 평균들을 빼고 svd 실행 후 평균을 다시 적용한다. 정규화를 위해서다.
깐깐한 사람은 점수를 대체적으로 적게 주고 관대한 사람은 점수를 후하게 줬을 것이기 때문에
각 사용자들의 평균을 빼 정규화 시켜준다.

각 사용자들의 평균을 빼면 이와 같이 평균보다 높은 점수는 양수로, 평균보다 낮은 점수는 음수로 나온다.

numpy matrix를 다시 dataFrame으로 바꿔서 보면 위와 같다.

svd를 사용하기 위해 scipy에서 가져온다.
적용해주면 U : 610X12
S : 12
Vt : 12X9724 ( V는 9724X12가 된다.)
S를 diagonal matrix로 만들기 위해 np.diag를 적용해보면,

위와 같이 대각선 원소들이 기존의 S로 채워진 것을 알 수 있다.

다시 np.dot를 이용해 U*S*Vt를 구하고 아까 뺐었던 평균을 더해준다.
<기존의 matrix>
이제 사용자의 기존 기록을 바탕으로 추천영화들을 뽑는 함수를 만들어보자.

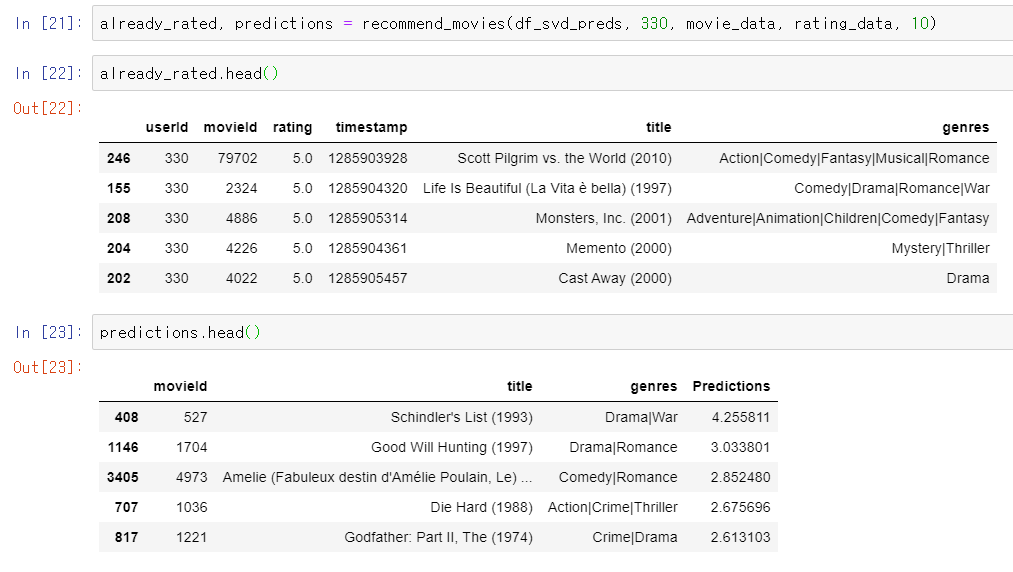
사용자 330의 추천영화 10개를 뽑아보면 위와 같이 나온다.
다음에는 banila-MF를 이용한 CF를 구현해보도록 하겠다.
참고 블로그 : https://lsjsj92.tistory.com/570
파이썬 Matrix Factorization 영화 추천 시스템(movie recommender system) 구현해보기 - 2
포스팅 개요 해당 글에 대한 코드는 아래 github 링크에 전부 올려두었습니다. https://github.com/lsjsj92/recommender_system_with_Python lsjsj92/recommender_system_with_Python recommender system with Pyt..
lsjsj92.tistory.com
'개발 > Recommender System' 카테고리의 다른 글
| 추천시스템 Recommender System 정리 (0) | 2020.05.26 |
|---|---|
| 추천시스템 Collaborative Filtering(CF) Python 기반 [4] (0) | 2020.05.08 |
| 추천시스템 Collaborative Filtering(CF) Python 기반 [2] (0) | 2020.05.06 |
| 추천시스템 Collaborative Filtering(CF) Python 기반 [1] (0) | 2020.04.27 |
| Pandas Library만을 이용하여 간단한 Content Based Filtering 구현하기 (0) | 2020.04.27 |




댓글